Putting DLI Data to Use A Computing Exercise
The following exercise provides a hands-on computing experience that introduces some basic approaches to quantitative analysis. Included in a workshop that was first presented at the 1996 Learned Socieities Congress and sponsored by the Humanities and Social Sciences Federation of Canada, the computing tasks below use a data file consisting of a subset of variables and cases drawn from the national Survey of Literacy Skills Used in Daily Activities, 1989. Initially, this customized data file and the instructions accompanying the exercise were prepared for use with the NSDStat statistical system. Subsequently, these products were modified for use with the SPSS statistical package. To complete this exercise, you require the following:
- a copy of the SPSS port file for the Literacy data,
- a copy of the data documentation accompanying this file, and
- access to the SPSS statistical package.
Becoming Familiar with the Data
Begin this exercise by familiarizing yourself with some of the variables in this customized data file. Using the accompanying data documentation, answer the following questions.
1. Below are some descriptions of variables appearing in the following statistical analyses. Identify the SPSS variable name for each item and then record the name in the table below. SPSS variables are specified under the ACRONYM field in the data documentation.
Which variable identifies province of residence?
| Description | SPSS Variable Name |
| Which variable captures the age of the respondents? | . |
| Which variable captures how often the respondents went to a public library? | . |
| Which variable contains the IRT Reading Ability score? | . |
| Which variable contains the four categorized reading levels? | . |
2. Use the data documentation to determine whether the following variables are categorical or analytic. The distinction between categorical and analytic measurement appears in Exploring Data Liberation. Knowing the measurement of a variable is important when considering the choice of a statistical procedure for an analysis. Check the column in the table below that matches each variable’s level of measurement.
| Variable Name | Measurement Level | |
|---|---|---|
| Categorical | Analytic | |
| PROV | . | . |
| AGECLPSD | . | . |
| Q11C | . | . |
| Q22A | . | . |
| SEX | . | . |
| Q41 | . | . |
| IRT Reading Ability | . | . |
| Reading Level | . | . |
Loading the Literacy Data File in SPSS
The customized file for this exercise has been saved as both an SPSS portable and system file. The system file, which was produced by processing the raw data in a previous SPSS/Windows session, contains just the data for the subset of cases and variables described in the accompanying data documentation. The system file is not readable by the eye but does include the data and all of the information declared for each variable, such as labels and missing values. The SPSS portable file is a text file version of this system file. However, the contents have been encoded to preserve the data and variable information in a format that is not machine dependent.
You must begin by retrieving a copy of either the portable or system file. Both are available at: ftp://datalib.library.ualberta.ca/pub. The SPSS system file is named dlilit89.sav while the portable version is named dlilit89.por. If you are using SPSS/Windows, the system file is the appropriate choice although the portable file also works. If you are using SPSS on any system other than Windows, retrieve only the portable file. Below is an example of retrieving a copy of the system file using ftp:
ftp datalib.library.ualberta.ca
anonymous
e-mail address
cd pub
binary
hash
get dlilit89.sav
quit
To load either the portable or system file in SPSS for Windows, begin the SPSS program and select the File option from the menu at the top of the SPSS window.
Next, select the Open option and specify the file type and location of the file on your machine.
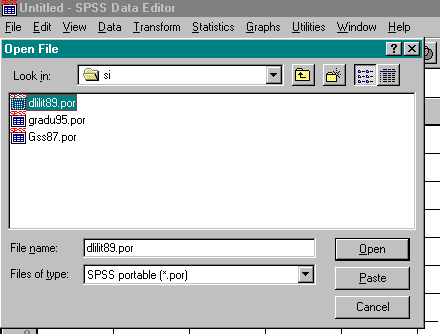
In the example shown, the file dlilit89.por in the directory si has been identified and declared as an SPSS portable file. Clicking on OPEN will load the data from this file into the current Data Editor (as shown in the following figure.)
You are now ready to complete the data analysis described below.
Descriptive Statistics: Working with Categorical Variables
Analysis Objective. When pursuing background about a policy issue, one question often asked is, “How big will be the impact?” Similarly, when investigating a social problem, the question typically becomes, “How many people face this problem?” One approach to answering either of these questions is to compute population estimates of the focal group. An estimate will provide some sense about the scale of the social problem or the impact of a particular social policy.
Analysis Issue. One concern in the late 80’s was the estimate of functional illiterates in Canada. Southam Press had conducted research in 1987 that suggested one in four adults in Canada were functionally illiterate. Statistics Canada conducted their own survey in 1989 to address this issue.
Using the summary variable for reading ability level (RDLEVELA) in the file loaded above, obtain population estimates for this variable. Initially, the frequencies for variables in this file are based on the sample size, that is, the number of respondents in this survey. Statistics Canada, however, has provided a variable that weights cases (1) to adjust for the sampling methodology employed in gathering the data and (2) to provide population estimates. Because not every case in the study had the same probability of being selected for this survey, a weight variable was added to correct for unequal probabilities. In addition, these corrections also rescale the frequencies to an estimate of the population from which the sample was drawn.
Exercise. To use the Statistics Canada weight variable in an analysis, SPSS must first be instructed to perform weighting and assigned the variable containing the weight values. In this instance, the name of the Statistics Canada weight variable is WGHT10. The script for making this assignment in SPSS is given below.
Determining a Population Estimate
From the menu bar, select Data and then Weight Cases.
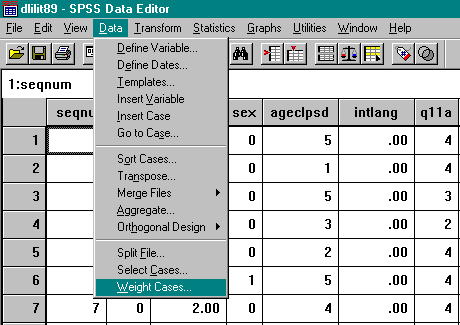
Click on the button to select “Weight cases by” and insert the variable WGHT10.
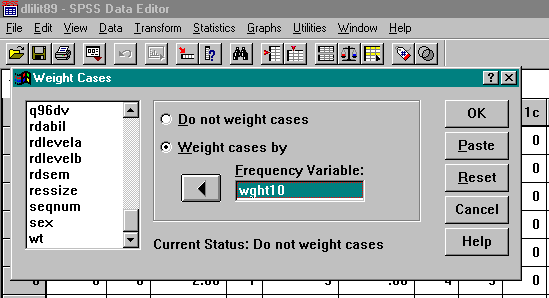
Click OK
You are now ready to obtain the frequencies for the reading level variable.
Select from the menu bar Statistics-Summarize-Frequencies and request the frequency distribution for RDLEVELA.
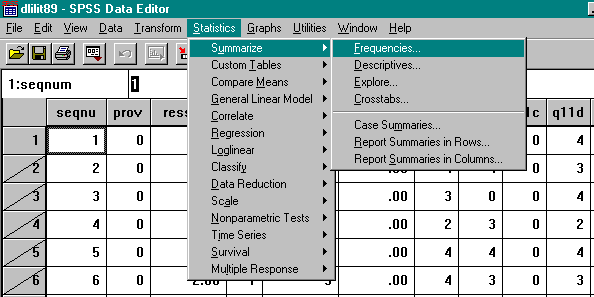
Complete the following information using the output on your monitor for the frequency distribution of RDLEVELA.
| Total Weighted N = |
| Number of Missing Cases = |
| RDLEVELA | Number or Frequency | Valid Percent |
| Level 1 | . | . |
| Level 2 | . | . |
| Level 3 | . | . |
| Level 4 | . | . |
Population Estimates Using the Approximate Variance Table
To work with population estimates from this study, Statistics Canada provides guidelines in its data documentation that should be followed. An example for reporting a population estimate for Level 1 reading ability using their guidelines is provided next. To complete this exercise, you will need to use both the Approximate Variance Table for Canada and the Sampling Variability Guidelines included in the data documentation accompanying this study.
| Step | Instruction | Answer |
|---|---|---|
| Step 1 | Record the weighted frequency for Level 1: | . |
| Step 2 | Round the figure in Step 1 nearest 1,000: | . |
| Step 3 | Using the Approximate Variance Table, look down the far left column the number closest to the figure in Step 2 (the table lists values in ‘000). Follow the string of asterisks to the right until you encounter a number. Record the value from this table: | . |
| Step 4 | Using the Sampling Variability Guidelines, compare the figure recorded in Step 3 with the table in the guidelines. How should the population estimate for Level 1 be reported according to the guidelines? | . |
Confidence Intervals Using the Approximate Variance Table
In the above exercise, you estimated a count in thousands. While the computer generated a precise number, the answer was rounded to the nearest thousand. This is done to avoid a sense of greater precision than exists. An alternative to reporting an exact count is to report a confidence interval, usually a 95% interval. In working with a confidence interval, one reports a range within which one believes the population value to exist. Thus, one would report that 19 out of 20 times, one would expect the confidence interval to contain the population count. Public opinion poll results are often reported using this approach. For example, a poll might reveal that 45% of the public would vote for the Liberal Party if an election were held today, plus or minus 4%, 19 out of 20 times. In other words, one would expect the Liberals to receive between 41% and 49% of the vote if the election were held on the day of the poll, where 41% is the lower confidence interval (45%-4%) and 49% is the upper confidence interval (45%+4%).
Using the above results for reading ability level, calculate a confidence interval for one of the percentages. This will entail a bit of simple arithmetic.
| Step | Instruction | Answer |
|---|---|---|
| Step 1 | Record the percentage of the population with a Level 3 reading ability level: | . |
| Step 2 | Convert the percentage into a proportion by dividing by 100, i.e., move the decimal point two places to the left and record the value: | . |
| Step 3 | Enter the weighted frequency for Level 3: | . |
| Step 4 | Round the figure in Step 3 nearest 1,000: | . |
| Step 5 | Using the Approximate Variance Table, look down the far left column for the number closest to the figure in Step 4 (remember the table lists values in ‘000). Follow the string of asterisks to the right until you encounter a number. Record the value from this table: | . |
| Step 6 | Convert the percentage in Step 5 to a proportion by dividing by 100, i.e., move the decimal point two places to the left and record the value: | . |
| Step 7 | A 95% confidence interval (CI95) brackets a parameter estimate and thus, consists of two values: an interval minimum and maximum. To calculate these values, complete the following equations:
CI95 minimum = .222 – ( 2 * .222 * .033), where .222 comes from Step 2, the 2 in parentheses is the approximate value for the 95% level and .033 is the coefficient of variation from Step 6. CI95 maximum = .222 + ( 2 * .222 * .033) |
. |
In interpreting the results, one would conclude that the percentage of adult Canadians with a reading ability at level three lies between 20.7% (the lower confidence interval) and 23.7% (the upper confidence interval).
Using a Subset of Cases and Calculating a Confidence Interval
The next exercise entails examining the distribution of the reading ability levels of just those respondents who have completed some secondary education. To approach an analysis in this way, one is looking at a special subpopulation and examining key dependent variables of this group. For example, what is the reading ability level of those who have some secondary education but who did not receive a secondary degree? This is what we will explore.
Turn to the data documentation and find the variable containing the respondent’s highest level of education. Next, identify the code used to classify those who “completed some secondary education.” Record your answers here.
| Variable Name of Respondent’s Highest Level of Education | Code for the Category: Completed Some Secondary Education: |
|---|---|
| . | . |
From the menu bar, select Data and Select cases.
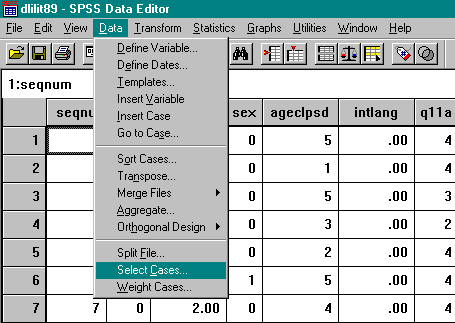
Select the button displayed as: If condition is satisfied
Press the IF button, which was activated by the previous step.
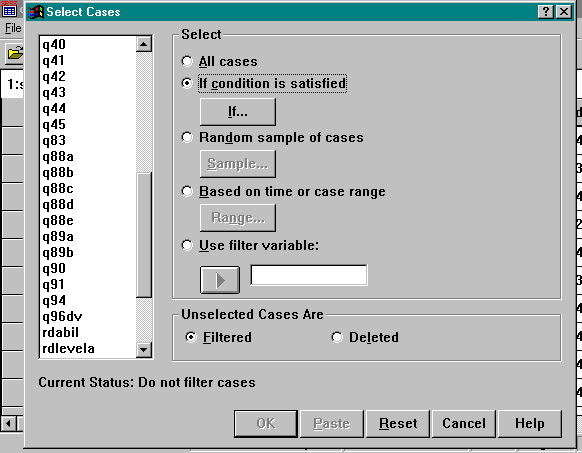
Select Q22A and complete the equation as follows: Q22A = 3
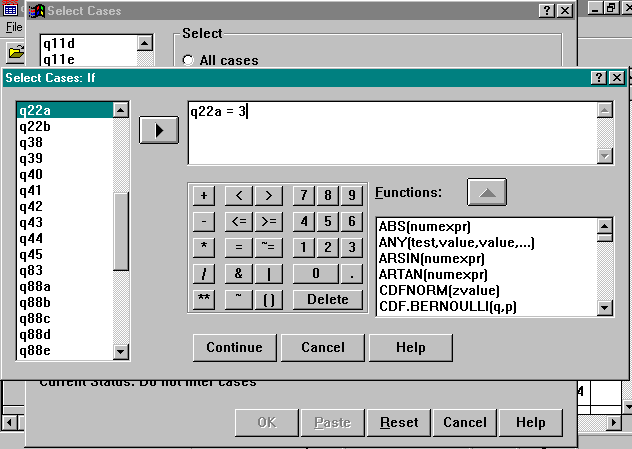
Click Continue and and then OK.
Notice that Filter On is reported below the horizontal scroll bar, which indicates a case selection is in effect.
Run the frequencies for RDLEVELA and complete the following table below.
| Total Weighted N = |
| Number of Missing Cases = |
| RDLEVELA | Number or Frequency | Valid Percent |
| Level 1 | . | . |
| Level 2 | . | . |
| Level 3 | . | . |
| Level 4 | . | . |
Using these results, calculate a confidence interval for the proportion with a Level 2 reading ability. Notice that using a subpopulation entails interpreting the Approximate Variance Table differently than the two previous exercises (see Step 5 below).
| Step | Instruction | Answer |
|---|---|---|
| Step 1 | Record the percentage of those with a Level 2 reading ability level: | . |
| Step 2 | Convert the percentage into a proportion by dividing by 100, i.e., move the decimal point two places to the left and record the value: | . |
| Step 3 | Enter the weighted frequency for Level 2: | . |
| Step 4 | Round the figure in Step 3 nearest 1,000: | . |
| Step 5 | Using the Approximate Variance Table, look down the far left column for the number closest to the figure in Step 4 (remember the table lists values in ‘000). Next, move across the columns at the top of the Table until you find a percentage close to the value in Step 1. The figure that intersects this row and column is the coefficient of variation to be used. Record the Table value: | . |
| Step 6 | Convert the percentage in Step 5 to a proportion by dividing by 100, i.e., move the decimal point two places to the left and record the value: | . |
| Step 7 | Calculate upper and lower 95% CI:
CI95 min = a – ( 2 * a * b), where a = the proportion from Step 2 and b is the coefficient of variation from Step 6. CI95 max = a + ( 2 * a * b), where a = the proportion from Step 2 and b is the coefficient of variation from Step 6. |
. |
Re-select All Cases and Change Weight Variables
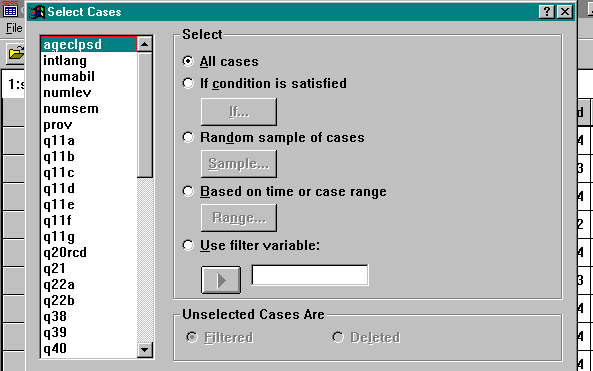
Next, turn off the filter that selected the subpopulation defined above so that subsequent analyses will use all of the cases. From the menu bar, select Data, Select Cases, then choose the button for All cases, and click OK.
The above weight variable not only corrected for the sampling methodology, but also produced population estimates. There are times when population estimates are not really required. Instead of wanting to know an estimate of the number of people in Canada with a certain attribute, the research focus is on the proportion or average of some property. Nevertheless, a weight variable is still required to adjust for the sampling methodology. Without this adjustment, the results cannot be generalized to the population. A second weight variable has been included with the Literacy work file that re-scales the weight variable back to the sample size, that is, to the size of the original sample rather than the estimated population size.
Now change the weight variable to the re-scaled weight variable, which is named, WT. From the menu bar, select Data, Weight Cases, replace WGHT10 with WT, and click OK.
 Figure 1: Doing Science
Figure 1: Doing Science Figure 2: Making Decisions
Figure 2: Making Decisions Figure 3: Data Focused Model
Figure 3: Data Focused Model

You must be logged in to post a comment.